We are in the process of curating a list of this year’s publications — including links to social media, lab websites, and supplemental material. Currently, we have 96 full papers, 19 posters, one journal paper, two interactive demos, two student mentoring programs and we lead six workshops. Three papers received a best paper award and 11 papers received an honorable mention.
Your publication from 2026 is missing? Please enter the details in this Google Forms and send us an email that you added a publication: contact@germanhci.de
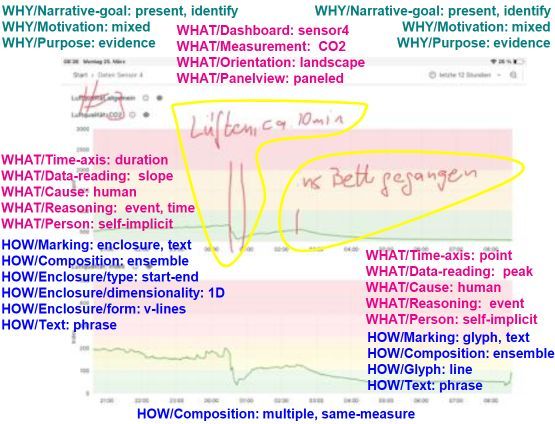
(De)Coding Lay Users' Annotations of Time-series Sensor Data from the Home
Albrecht Kurze (TU Chemnitz), Alexa Becker (HS Anhalt), Jana Bergk (TU Chemnitz), Christin Reuter (TU Chemnitz)
Abstract | Tags: Posters | Links:
@inproceedings{Kurze2026DecodingLay,
title = {(De)Coding Lay Users' Annotations of Time-series Sensor Data from the Home},
author = {Albrecht Kurze (TU Chemnitz), Alexa Becker (HS Anhalt), Jana Bergk (TU Chemnitz), Christin Reuter (TU Chemnitz)},
url = {https://www.tu-chemnitz.de/informatik/mi/, website https://wisskomm.social/@tucmi, lab's social media https://hci.social/@AlbrechtKurze, author's hci.social},
doi = {10.1145/3772363.3798962},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {Annotation through additional graphic and textual elements is a helpful means of enriching visualizations. Previous work analyzing such annotations is primarily focused on infographics created by experts and tends to be generic for many different types of data and visualizations. In this work, we focus on the analysis of annotations of time-series data of simple sensors (e.g. light, temperature) from the smart home created by lay users. We take into account specifics of this context (type of data, home environment, limited expertise) and present the current status of our taxonomy that allows analyzing the WHY, WHAT, and HOW of such annotations. Our taxonomy is intended to analyze a large number of annotations created in smart home field studies. In the long-term this will inform implications for design to support lay users' data interaction with smart home data in sensemaking as well as annotation and data management workflows.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}
BotaXplore: Enhancing Visitor Engagement and Learning in Botanical Gardens Through Mobile Technology
Albin Zeqiri (Ulm University), Tobias Wagner (Ulm University), Johanna Grüneberg (LMU Munich), Enrico Rukzio (Ulm University)
Abstract | Tags: Posters | Links:
@inproceedings{Zeqiri2026Botaxplore,
title = {BotaXplore: Enhancing Visitor Engagement and Learning in Botanical Gardens Through Mobile Technology},
author = {Albin Zeqiri (Ulm University), Tobias Wagner (Ulm University), Johanna Grüneberg (LMU Munich), Enrico Rukzio (Ulm University)},
url = {https://www.uni-ulm.de/in/mi/hci/, website
https://az16.github.io/, author's social media
https://wgnrto.de/, author's social media},
doi = {10.1145/3772363.3799272},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {Educational guided visits in botanical gardens offer valuable opportunities for learning and engagement that promote awareness of the importance of biological diversity, its conservation, and sustainable use. However, a focus group with five botanists identified challenges in designing tours for heterogeneous audiences that foster curiosity and interest, as well as in tailoring educational content. To address these aspects, this paper presents BotaXplore, a prototype mobile application that supports plant exploration and learning in botanical gardens through three modes: exploratory, semi-guided, and tour-based. Using photo-based identification, users access short facts and quizzes about plants, and discovered species are added to a personal collection. Building on this prototype, we plan to evaluate the app's impact on nature engagement and learning outcomes after improving learning paths, content generation, and support for collaborative exploration.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}

Enhancing Memory Recall Through AI-Assisted Method of Loci in Virtual Reality
Clemens Wulff (Universität Hamburg), Lucie Kruse (Universität Hamburg), Frank Steinicke (Universität Hamburg)
Abstract | Tags: Posters | Links:
@inproceedings{Wulff2026EnhancingMemory,
title = {Enhancing Memory Recall Through AI-Assisted Method of Loci in Virtual Reality},
author = {Clemens Wulff (Universität Hamburg), Lucie Kruse (Universität Hamburg), Frank Steinicke (Universität Hamburg)},
url = {https://www.inf.uni-hamburg.de/en/inst/ab/hci.html, website
https://www.linkedin.com/in/lucie-kruse-004740234/, author's linkedin},
doi = {10.1145/3772363.3798815},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {The Method of Loci is a well-established mnemonic technique that involves associating words with objects placed along a route. A key factor in its effectiveness is creating meaningful connections between the words to-be-remembered and the corresponding objects. In this study, we investigate how artificial intelligence (AI) can enhance this technique by i) selecting appropriate objects for each word and ii) generating coherent textual associations between the words and their objects. These AI-assisted approaches are compared to a control condition, where iii) object-word pairs are chosen randomly without assistance. Our findings demonstrate that the Object condition significantly improves word recall both immediately and after one week. On the other side, the Text condition did not lead to a significant enhancement in recall, and perceived workload showed no significant differences across all conditions. These results offer valuable insights for advancing mnemonic techniques and suggest directions for future research to optimize memory strategies.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}
Enhancing mHealth App Onboarding Using a Multimodal Mixed Reality Avatar
Stefan Resch (Frankfurt University of Applied Sciences, Germany, University of Cadiz, Spain), Yunus Söyleyici (Frankfurt University of Applied Sciences), Valentin Schwind (Stuttgart Media University), Diana Völz (Frankfurt University of Applied Sciences), Daniel Sanchez-Morillo (University of Cadiz)
Abstract | Tags: Posters | Links:
@inproceedings{Resch2026EnhancingMhealth,
title = {Enhancing mHealth App Onboarding Using a Multimodal Mixed Reality Avatar},
author = {Stefan Resch (Frankfurt University of Applied Sciences, Germany, University of Cadiz, Spain), Yunus Söyleyici (Frankfurt University of Applied Sciences), Valentin Schwind (Stuttgart Media University), Diana Völz (Frankfurt University of Applied Sciences), Daniel Sanchez-Morillo (University of Cadiz)},
url = {https://www.frankfurt-university.de/mixed-reality-lab/, website
https://www.linkedin.com/in/stefan-resch96, author's linkedin},
doi = {10.1145/3772363.3799298},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {Navigating novel smartphone applications is often complex and unintuitive during the initial onboarding phase. Missing or ineffective guidance can cause misuse, errors, and abandonment, which is particularly critical in domains such as mobile Health (mHealth) apps. While previous research has shown potential for onboarding with conversational avatars in mixed reality (MR), the impact of avatars combining gestures and voice for app tutorial guidance remains unknown. To address this gap, we conducted a within-subject study with 24 participants using a smart insole mHealth app as a case example. Participants completed tasks in MR under four conditions varying the presence of avatar voice and animated pointing gestures. Our findings show that tutorial guidance improved with voice and gesture compared to no avatar support, enhancing usability and learning experience while also highlighting remaining challenges. We contribute design implications for avatar-supported guidance in mHealth and broader Human-Computer Interaction (HCI) contexts.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}
Eye Want It All! Investigating Eye Tracking as Implicit Support for Generative Inpainting
Niklas Pfützenreuter (University of Duisburg-Essen), Carina Liebers (University of Duisburg-Essen), David Goedicke (University of Duisburg-Essen), Donald Degraen (University of Canterbury), Uwe Gruenefeld (GENERIO), Stefan Schneegass (University of Duisburg-Essen)
Abstract | Tags: Posters | Links:
@inproceedings{Pfuetzenreuter2026EyeWant,
title = {Eye Want It All! Investigating Eye Tracking as Implicit Support for Generative Inpainting},
author = {Niklas Pfützenreuter (University of Duisburg-Essen), Carina Liebers (University of Duisburg-Essen), David Goedicke (University of Duisburg-Essen), Donald Degraen (University of Canterbury), Uwe Gruenefeld (GENERIO), Stefan Schneegass (University of Duisburg-Essen)},
url = {https://hci.informatik.uni-due.de/, website
https://de.linkedin.com/company/hci-group-essen, lab's linkedin
https://www.linkedin.com/in/niklas-pfützenreuter/, author's linkedin
https://www.facebook.com/HCIEssen, facebook},
doi = {10.1145/3772363.3799314},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {Users often struggle to use Generative Artificial Intelligence (GenAI) models to generate a desired image, as controlling them solely with prompts is difficult. Current solutions to this problem, such as adding conditional controls, require users to provide explicit input, which can be tedious. To avoid depending on additional explicit input, this paper explores what implicit gaze behavior tells about user intentions when viewing generated images. In our user study (𝑁 = 16), we evaluated the correlation between gaze behavior and user annotations, showing that users looked longer at areas they wanted to regenerate. While our research is the first step, we believe our work can pave the way for incorporating implicit user input into interactions with GenAI systems.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}
Feeds Don't Tell the Whole Story: Measuring Online-Offline Emotion Alignment
Sina Elahimanesh (Saarland University), Mohammadali Mohammadkhani (Saarland University), Shohreh Kasaei (Sharif University of Technology)
Abstract | Tags: Posters | Links:
@inproceedings{Elahimanesh2026FeedsDontb,
title = {Feeds Don't Tell the Whole Story: Measuring Online-Offline Emotion Alignment},
author = {Sina Elahimanesh (Saarland University), Mohammadali Mohammadkhani (Saarland University), Shohreh Kasaei (Sharif University of Technology)},
url = {https://www.youtube.com/watch?v=L4ltIOXd9dU, teaser video
https://www.linkedin.com/in/sina-elahimanesh/, author's linkedin},
doi = {10.1145/3772363.3795008},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {In contemporary society, social media is deeply integrated into daily life, yet emotional expression often differs between real and online contexts. We studied the Persian community on X to explore this gap, designing a human-centered pipeline to measure alignment between real-world and social media emotions. Recent tweets and images of participants were collected and analyzed using Transformers-based text and image sentiment modules. Friends of participants provided insights into their real-world emotions, which were compared with online expressions using a distance criterion. The study involved N=105 participants, 393 friends, over 8,300 tweets, and 2,000 media images. Results showed only 28% similarity between images and real-world emotions, while tweets aligned about 76% with participants' real-life feelings. Statistical analyses confirmed significant disparities in sentiment proportions across images, tweets, and friends' perceptions, highlighting differences in emotional expression between online and offline environments and demonstrating practical utility of the proposed pipeline for understanding digital self-presentation.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}
Feeds Don't Tell the Whole Story: Measuring Online-Offline Emotion Alignment
Sina Elahimanesh (Saarland University), Mohammadali Mohammadkhani (Saarland University), Shohreh Kasaei (Sharif University of Technology)
Abstract | Tags: Posters | Links:
@inproceedings{Elahimanesh2026FeedsDont,
title = {Feeds Don't Tell the Whole Story: Measuring Online-Offline Emotion Alignment},
author = {Sina Elahimanesh (Saarland University), Mohammadali Mohammadkhani (Saarland University), Shohreh Kasaei (Sharif University of Technology)},
url = {https://www.youtube.com/watch?v=L4ltIOXd9dU, teaser video
https://www.linkedin.com/in/sina-elahimanesh/, author's linkedin},
doi = {10.1145/3772363.3795008},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {In contemporary society, social media is deeply integrated into daily life, yet emotional expression often differs between real and online contexts. We studied the Persian community on X to explore this gap, designing a human-centered pipeline to measure alignment between real-world and social media emotions. Recent tweets and images of participants were collected and analyzed using Transformers-based text and image sentiment modules. Friends of participants provided insights into their real-world emotions, which were compared with online expressions using a distance criterion. The study involved N=105 participants, 393 friends, over 8,300 tweets, and 2,000 media images. Results showed only 28% similarity between images and real-world emotions, while tweets aligned about 76% with participants' real-life feelings. Statistical analyses confirmed significant disparities in sentiment proportions across images, tweets, and friends' perceptions, highlighting differences in emotional expression between online and offline environments and demonstrating practical utility of the proposed pipeline for understanding digital self-presentation.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}
It’s Not Just the Prompt: Model Choice Dominates LLM Creative Output
Jennifer Haase (Weizenbaum Institute, Berlin, Germany), Jana Gonnermann-Müller (Zuse Institute Berlin, Berlin, Germany), Paul H. P. Hanel (Essex University, Essex, United Kingdom), Nicolas Leins (Zuse Institute Berlin, Berlin, Germany), Thomas Kosch (HU Berlin, Berlin, Germany), Jan Mendling (HU Berlin, Berlin, Germany), Sebastian Pokutta (Zuse Institute Berlin, Berlin, Germany)
Abstract | Tags: Posters | Links:
@inproceedings{Haase2026ItsNot,
title = {It’s Not Just the Prompt: Model Choice Dominates LLM Creative Output},
author = {Jennifer Haase (Weizenbaum Institute, Berlin, Germany), Jana Gonnermann-Müller (Zuse Institute Berlin, Berlin, Germany), Paul H. P. Hanel (Essex University, Essex, United Kingdom), Nicolas Leins (Zuse Institute Berlin, Berlin, Germany), Thomas Kosch (HU Berlin, Berlin, Germany), Jan Mendling (HU Berlin, Berlin, Germany), Sebastian Pokutta (Zuse Institute Berlin, Berlin, Germany)},
url = {https://www.weizenbaum-institut.de/forschung/digitale-infrastrukturen-in-der-demokratie/sicherheit-und-transparenz-digitaler-prozesse/, website
https://jenniferhaase.com/, author's social media},
doi = {10.1145/3772363.3799284},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {Prompt engineering is often treated as a reliable control mechanism for LLM behavior, yet LLM outputs vary even under similar prompts due to stochasticity. We quantify how much output variance is driven by prompt choice versus model choice and by inherent within-LLM stochasticity by evaluating 12 LLMs on 10 creativity prompts in an open-ended divergent-thinking task (AUT), measuring answer quality (originality) and quantity (number of answers), generating 100 samples per prompt. Then, we partition the variance into model, prompt, within-LLM stochasticity, and model x prompt interaction components. Our findings show that model choice is at least as important as prompt choice in this setting. For originality, the model explains 41% of the variance. Prompts explain 36%, and within-model stochasticity explains 11%. For fluency, prompts explain 4% of the variance. Model choice explains 51%, and within-model stochasticity 34%. Beyond variance decomposition, models exhibit persistent "creative fingerprints'' in thematic preferences and formatting habits.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}
Maintaining Stable Personas? Examining Temporal Stability in LLM-Based Human Simulation
Jana Gonnermann-Müller (Zuse Institute Berlin), Jennifer Haase (Humboldt-University Berlin, Weizenbaum Institute), Nicolas Leins (Zuse Institute Berlin), Thomas Kosch (Humboldt-University Berlin), Sebastian Pokutta (Zuse Institute Berlin)
Abstract | Tags: Posters | Links:
@inproceedings{GonnermannMueller2026MaintainingStable,
title = {Maintaining Stable Personas? Examining Temporal Stability in LLM-Based Human Simulation},
author = {Jana Gonnermann-Müller (Zuse Institute Berlin), Jennifer Haase (Humboldt-University Berlin, Weizenbaum Institute), Nicolas Leins (Zuse Institute Berlin), Thomas Kosch (Humboldt-University Berlin), Sebastian Pokutta (Zuse Institute Berlin)},
url = {https://hcistudio.org/, website
https://iol.zib.de/team/jana-gonnermannmueller.html, author's social media},
doi = {10.1145/3772363.3799334},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {Large language models (LLMs) are increasingly employed in Human-Computer Interaction (HCI) research to simulate human behavior for prototype testing and social simulations. The validity of these interactions rests on the assumption that LLMs maintain stable personas. Our work investigates temporal stability in LLM-based human simulation, examining both stability across independent instantiations and within extended interactions. We combined self-reports with observer-ratings of four persona intensity levels (low, moderate, and high ADHD representations, default persona), seven LLMs, and three persona prompts. Results from N = 3, 473 conversations and N = 4, 054 assessments indicate that LLMs generally reproduce personas across conversations in self-reports and observer ratings, suggesting that LLMs hold promise as tools for simulating human behavior. Within extended 18-turn interactions, observer ratings reveal a decline for moderate and high personas, a discrepancy that warrants further investigation. Our findings indicate methodological considerations for HCI researchers employing LLM-based human simulation and implications for future research.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}
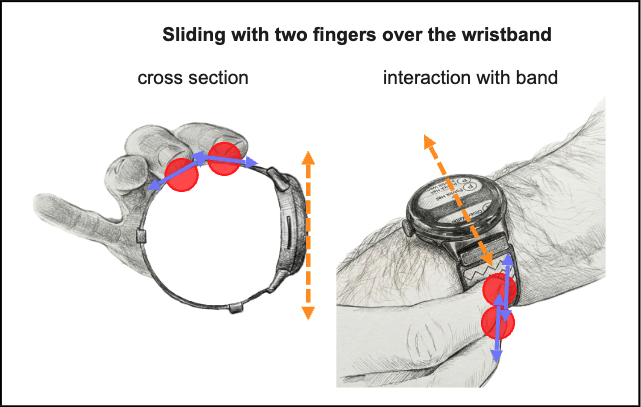
MultiBand: Adding Multi-Touch to the Smartwatch Wristband for Extended Interaction
David Petersen (Technische Hochschule Köln), Marvin Reuter (Technische Hochschule Köln), Matthias Böhmer (Technische Hochschule Köln)
Abstract | Tags: Posters | Links:
@inproceedings{Petersen2026Multiband,
title = {MultiBand: Adding Multi-Touch to the Smartwatch Wristband for Extended Interaction},
author = {David Petersen (Technische Hochschule Köln), Marvin Reuter (Technische Hochschule Köln), Matthias Böhmer (Technische Hochschule Köln)},
url = {https://moxd.io/, website
https://www.instagram.com/moxdlab/, instagram},
doi = {10.1145/3772363.3799304},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {The small screen size of smartwatches presents input challenges due to the limited touch surface and screen occlusion. To expand the input space and mitigate the fat finger problem, extensive research has explored various strategies for improving smartwatch interaction design. While wristband-based input has also been studied, there is a lack of research on multi-touch interaction and gestures performed directly on the band. To address this gap, we present MultiBand, a functional prototype that expands smartwatch input capabilities by leveraging capacitive touch sensors around the wristband. Our prototype enables users to execute different functions on a smartwatch based on how they place their fingers on the wristband. Our implementation distinguishes between two types of finger interactions to trigger different scrolling techniques when navigating a contact list. We contribute the software and hardware of our prototype as well as first insights from preliminary user tests.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}
Open Challenges of Immersive AI-based Remembrance Systems using the Example of Interactive Digital Testimonies
Daniel Kolb (Leibniz Supercomputing Centre), Fabian Heindl (Ludwig-Maximilians–Universität München), Markus Gloe (Ludwig-Maximilians–Universität München), Dieter Kranzlmüller (Ludwig-Maximilians–Universität München)
Abstract | Tags: Posters | Links:
@inproceedings{Kolb2026OpenChallenges,
title = {Open Challenges of Immersive AI-based Remembrance Systems using the Example of Interactive Digital Testimonies},
author = {Daniel Kolb (Leibniz Supercomputing Centre), Fabian Heindl (Ludwig-Maximilians–Universität München), Markus Gloe (Ludwig-Maximilians–Universität München), Dieter Kranzlmüller (Ludwig-Maximilians–Universität München)},
url = {https://www.lrz.de/en/technologies/virtual-reality, website
https://www.linkedin.com/in/daniel-kolb-999628129/, author's linkedin},
doi = {10.1145/3772363.3799277},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {Immersive AI-based remembrance systems offer users various ways to interact with recordings or recreations of living and deceased individuals. This includes simulated face-to-face conversations based on authentic recordings, such as in Interactive Digital Testimonies. Their potential application ranges from supporting family members during times of grief to educating learners on historical events. Using this example, we shed light on nine as-of-yet unresolved fundamental challenges of immersive AI-based remembrance systems. Given the complexity and relativity of these challenges, we emphasize the need for concerted research across a broad range of scientific and humanities disciplines.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}
Seeing Thinking with the Abacus: Making Embodied Reasoning Visible Through Hybrid Sensing
Wisanukorn Boribun (Interaction Design Lab, University of Applied Sciences Potsdam)(Bauhaus-Universität Weimar), Frank Heidmann (Interaction Design Lab, University of Applied Sciences Potsdam), Eva Hornecker (Bauhaus-Universität Weimar)
Abstract | Tags: Posters | Links:
@inproceedings{Boribun2026SeeingThinking,
title = {Seeing Thinking with the Abacus: Making Embodied Reasoning Visible Through Hybrid Sensing},
author = {Wisanukorn Boribun (Interaction Design Lab, University of Applied Sciences Potsdam)(Bauhaus-Universität Weimar), Frank Heidmann (Interaction Design Lab, University of Applied Sciences Potsdam), Eva Hornecker (Bauhaus-Universität Weimar)},
url = {https://www.uni-weimar.de/en/media/chairs/computer-science-department/human-computer-interaction/, website},
doi = {10.1145/3772363.3798514},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {As accuracy and performance increasingly dominate interactive systems, the temporal processes through which human understanding develops often recede into the background. Reasoning unfolds gradually through action, inspection, hesitation, and revision. In this paper, we investigate how embodied reasoning during physical calculation can be made perceptible by attending to how people act, look, and pause while interacting with a material artifact. We present a hybrid sensing prototype centered on a physical abacus that combines gaze, head movement, and bead manipulation to respond to moments of inspection as they emerge. Rather than displaying information continuously or inferring cognitive states, the system briefly surfaces numerical feedback when interaction patterns indicate checking or reflection. Findings suggest that usefulness depended less on what information was shown and more on when it appeared. We argue for interaction aligned with human sense-making rhythms, in which system responses follow observable reasoning activity without directing or accelerating it.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}
Smart Insole Visual Foot Pressure Feedback in Mixed Reality Environments: Impact on Gait, Heart Rate, Workload, and Engagement in Treadmill Walking
Stefan Resch (Frankfurt University of Applied Sciences, Germany, University of Cadiz, Spain), Jean-Gabriel Hanania (Frankfurt University of Applied Sciences), Valentin Schwind (Stuttgart Media University), Diana Völz (Frankfurt University of Applied Sciences), Daniel Sanchez-Morillo (University of Cadiz)
Abstract | Tags: Posters | Links:
@inproceedings{Resch2026SmartInsole,
title = {Smart Insole Visual Foot Pressure Feedback in Mixed Reality Environments: Impact on Gait, Heart Rate, Workload, and Engagement in Treadmill Walking},
author = {Stefan Resch (Frankfurt University of Applied Sciences, Germany, University of Cadiz, Spain), Jean-Gabriel Hanania (Frankfurt University of Applied Sciences), Valentin Schwind (Stuttgart Media University), Diana Völz (Frankfurt University of Applied Sciences), Daniel Sanchez-Morillo (University of Cadiz)},
url = {https://www.frankfurt-university.de/mixed-reality-lab/, website
https://www.linkedin.com/in/stefan-resch96, author's linkedin},
doi = {10.1145/3772363.3799326},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {Although orthotic footwear supports the rehabilitation of lower-limb injuries, it often impairs natural gait control. Due to the lack of additional feedback, patients are unaware of abnormal foot pressure distributions, which can hinder recovery. Prior work has demonstrated the potential of virtual and mixed reality (VR/MR) for gait training with visual feedback. However, it remains unclear how smart insole pressure feedback affects gait and user experience in VR/MR. We conducted a within-subject study with 24 participants, testing four visual feedback modalities across three virtual environments during treadmill walking. Quantitative and qualitative results showed that a virtual forest altered gait, increased engagement, and reduced workload, while a pressure heatmap influenced objective and subjective measures depending on the environment. We provide empirical insights on foot augmentation in immersive settings and contribute design recommendations for future VR/MR gait training applications.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}
Stars Without Steps: Bridging Observatory Access Based on Physical Proximity Through Educational XR
Clara Sayffaerth (LMU Munich), Jennifer Meiler (LMU Munich), Crystal McArdle-Ventura (Wellesley College), Atakan Çoban (LMU Munich), Christoph Hoyer (LMU Munich), Florian Müller (TU Darmstadt), Arno Riffeser (LMU Munich), Jochen Kuhn (LMU Munich), Albrecht Schmidt (LMU Munich)
Abstract | Tags: Posters | Links:
@inproceedings{Sayffaerth2026StarsWithout,
title = {Stars Without Steps: Bridging Observatory Access Based on Physical Proximity Through Educational XR},
author = {Clara Sayffaerth (LMU Munich), Jennifer Meiler (LMU Munich), Crystal McArdle-Ventura (Wellesley College), Atakan Çoban (LMU Munich), Christoph Hoyer (LMU Munich), Florian Müller (TU Darmstadt), Arno Riffeser (LMU Munich), Jochen Kuhn (LMU Munich), Albrecht Schmidt (LMU Munich)},
url = {https://www.medien.ifi.lmu.de/, website
https://www.linkedin.com/company/lmu-media-informatics-group/, lab's linkedin
https://www.linkedin.com/in/sayffaerth/, author's linkedin},
doi = {10.1145/3772363.3799340},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {Remote research facilities such as mountain observatories offer unique scientific and educational value, yet their physical inaccessibility limits participation for many audiences. This paper presents a location-independent, mobile Extended Reality (XR) application that extends the experiential reach of a mountain-based observatory beyond its geographic constraints. The application allows users to virtually explore a research telescope and interactively learn about the observatory’s scientific work, instrumentation, and operational principles. Following interviews with on-site visitors to identify access barriers and learning needs, we developed an XR experience and evaluated it in an in-the-wild study with three school classes (N = 35). We deployed the application across three contexts (remote location, intermediate plateau, mountain summit) and assessed factors such as mental load, presence, motivation, perceived access, and quiz results. Our findings indicate that context-dependent physical proximity influences all factors except the quiz outcome, highlighting the importance of proximity-aware design for future XR systems.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}

TARDIS: Tabletop Augmented Reality for Dynamic Immersive Storytelling
Paul Preuschoff (RWTH Aachen University), René Schäfer (RWTH Aachen University), Phillip Ahlers (RWTH Aachen University). David Gilbert (RWTH Aachen University), Jan Borchers (RWTH Aachen University)
Abstract | Tags: Posters | Links:
@inproceedings{Preuschoff2026Tardis,
title = {TARDIS: Tabletop Augmented Reality for Dynamic Immersive Storytelling},
author = {Paul Preuschoff (RWTH Aachen University), René Schäfer (RWTH Aachen University), Phillip Ahlers (RWTH Aachen University). David Gilbert (RWTH Aachen University), Jan Borchers (RWTH Aachen University)},
url = {hci.ac, website
https://www.linkedin.com/in/paul-preuschoff/, author's linkedin},
doi = {10.1145/3772363.379929},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {In tabletop role-playing games, players experience a shared story, coordinated by a game master. This relies heavily on immersion, social interaction, and creative freedom. We explore how VR can increase immersion without undermining these other qualities. We placed players into a CAVE VR system to display virtual environments (VEs) on the walls and floor without requiring glasses that might impede social interaction. We varied how closely VEs textitmatched the game setting described verbally, from reflecting its general atmosphere to being true to details, and investigated impact on immersion, distraction, creativity, and role-play. Players feel more connected to their characters when seeing what their characters would see, but abstract, atmospheric VEs led to fewer problematic divergences and more creative freedom. Surprisingly, medium matching levels were often criticized because players could trust neither what they saw nor their ``cinema of the mind''. Our findings help integrate VR into shared collocated storytelling.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}
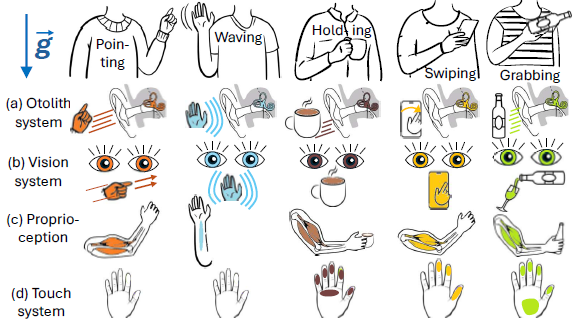
The Impact of Graviception on Human-Computer Interaction
Jean Vanderdonckt (Université Catholique de Louvain), Philippe Lefevre (Université Catholique de Louvain), Radu-Daniel Vatavu (Stefan cel Mare University of Suceava), Nuwan T Attygalle (Université Catholique de Louvain), Laura-Bianca Bilius (Stefan cel Mare University of Suceava), Gaëlle Calvary (Grenoble Institute of Technology), Sophie Dupuy-Chessa (Univ. Grenoble Alpes), Merle Fairhurst (TU Dresden), Tommy Nilsson (Fraunhofer FIT), Leif Oppermann (Fraunhofer FIT), Paolo Roselli (Tor Vergata University of Rome), Giovanni Saggio (Tor Vergata University of Rome), Valérie Swaen (Université Catholique de Louvain)
Abstract | Tags: Posters | Links:
@inproceedings{Vanderdonckt2026ImpactGraviception,
title = {The Impact of Graviception on Human-Computer Interaction},
author = {Jean Vanderdonckt (Université Catholique de Louvain), Philippe Lefevre (Université Catholique de Louvain), Radu-Daniel Vatavu (Stefan cel Mare University of Suceava), Nuwan T Attygalle (Université Catholique de Louvain), Laura-Bianca Bilius (Stefan cel Mare University of Suceava), Gaëlle Calvary (Grenoble Institute of Technology), Sophie Dupuy-Chessa (Univ. Grenoble Alpes), Merle Fairhurst (TU Dresden), Tommy Nilsson (Fraunhofer FIT), Leif Oppermann (Fraunhofer FIT), Paolo Roselli (Tor Vergata University of Rome), Giovanni Saggio (Tor Vergata University of Rome), Valérie Swaen (Université Catholique de Louvain)},
url = {https://www.fit.fraunhofer.de/en/business-areas/cooperation-systems/mixed-reality.html, website
https://www.linkedin.com/company/fraunhofer-fit/, lab's linkedin
https://www.linkedin.com/in/leifoppermann/, author's linkedin
https://www.youtube.com/@fit4xr, social media},
doi = {10.1145/3772363.3799280},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {Graviception, the human sensory perception of gravity and body orientation, plays a fundamental, yet often overlooked, role in how individuals interact with interactive systems. Human–computer interaction has traditionally emphasized visual, auditory, and tactile modalities, while comparatively neglecting the influence of gravity perception on embodiment, attention, motor control, and user experience. This paper synthesizes findings from neurophysiology, cognitive science, and biomechanical research to articulate how graviception impacts interaction, especially in immersive, hypogravity environments, mobile contexts, and accessibility. By positioning graviception as a first-class concern in embodied interaction, we suggest actionable implications for interaction design that consider graviceptive factors for designers and researchers developing future graviceptive-aware interactive systems.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}
Topic Matters: How Linguistic Properties can Shape Reading Behaviour in Selective Exposure Studies
Thomas Krämer (GESIS - Leibniz Institute for the Social Sciences), Dagmar Kern (GESIS - Leibniz Institute for the Social Sciences), Thomas Kosch (HU Berlin), Daniel Hienert (GESIS - Leibniz Institute for the Social Sciences)
Abstract | Tags: Posters | Links:
@inproceedings{Kraemer2026TopicMatters,
title = {Topic Matters: How Linguistic Properties can Shape Reading Behaviour in Selective Exposure Studies},
author = {Thomas Krämer (GESIS - Leibniz Institute for the Social Sciences), Dagmar Kern (GESIS - Leibniz Institute for the Social Sciences), Thomas Kosch (HU Berlin), Daniel Hienert (GESIS - Leibniz Institute for the Social Sciences)},
url = {https://www.hcistudio.org, website},
doi = {10.1145/3772363.3799294},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {Research on selective exposure frequently relies on eye tracking to study reading behaviour, often assuming that texts across different controversial topics are comparable once basic controls are applied. This assumption is problematic if topic-dependent linguistic properties systematically shape how users read and allocate attention. We therefore examine whether such properties relate to differences in reading behaviour in selective exposure contexts. We analyse linguistic features and eye-tracking data from a laboratory study in which 68 participants searched for and read news articles on climate change and migration policy. Our results reveal systematic differences in both textual characteristics and reading behaviour across topics. These findings identify an important methodological confound in selective exposure research and highlight the need to account for topic-specific linguistic properties when interpreting eye-tracking measures and designing systems intended to mitigate biased information consumption.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}
ViDscribe: Multimodal AI for Customizing Audio Description and Question Answering in Online Videos
Maryam S Cheema* (Arizona State University), Sina Elahimanesh* (Saarland University), Pooyan Fazli (Arizona State University), Hasti Seifi (Arizona State University)
Abstract | Tags: Posters | Links:
@inproceedings{Cheema2026Vidscribe,
title = {ViDscribe: Multimodal AI for Customizing Audio Description and Question Answering in Online Videos},
author = {Maryam S Cheema* (Arizona State University), Sina Elahimanesh* (Saarland University), Pooyan Fazli (Arizona State University), Hasti Seifi (Arizona State University)},
url = {https://www.linkedin.com/in/sina-elahimanesh/, author's linkedin},
doi = {10.1145/3772363.3793175},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {Advances in multimodal large language models enable automatic video narration and question answering (VQA), offering scalable alternatives to labor-intensive, human-authored audio descriptions (ADs) for blind and low vision (BLV) viewers. However, prior AI-driven AD systems rarely adapt to the diverse needs and preferences of BLV individuals across videos and are typically evaluated in controlled, single-session settings. We present ViDscribe, a web-based platform that integrates AI-generated ADs with six types of user customizations and a conversational VQA interface for YouTube videos. Through a longitudinal, in-the-wild study with eight BLV participants, we examine how users engage with customization and VQA features over time. Our results show sustained engagement with both features and that customized ADs improve effectiveness, enjoyment, and immersion compared to default ADs, highlighting the value of personalized, interactive video access for BLV users.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}
ViDscribe: Multimodal AI for Customizing Audio Description and Question Answering in Online Videos
Maryam S Cheema* (Arizona State University), Sina Elahimanesh* (Saarland University), Pooyan Fazli (Arizona State University), Hasti Seifi (Arizona State University)
Abstract | Tags: Posters | Links:
@inproceedings{Cheema2026Vidscribeb,
title = {ViDscribe: Multimodal AI for Customizing Audio Description and Question Answering in Online Videos},
author = {Maryam S Cheema* (Arizona State University), Sina Elahimanesh* (Saarland University), Pooyan Fazli (Arizona State University), Hasti Seifi (Arizona State University)},
url = {https://www.linkedin.com/in/sina-elahimanesh/, author's linkedin},
doi = {10.1145/3772363.3793175},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {Advances in multimodal large language models enable automatic video narration and question answering (VQA), offering scalable alternatives to labor-intensive, human-authored audio descriptions (ADs) for blind and low vision (BLV) viewers. However, prior AI-driven AD systems rarely adapt to the diverse needs and preferences of BLV individuals across videos and are typically evaluated in controlled, single-session settings. We present ViDscribe, a web-based platform that integrates AI-generated ADs with six types of user customizations and a conversational VQA interface for YouTube videos. Through a longitudinal, in-the-wild study with eight BLV participants, we examine how users engage with customization and VQA features over time. Our results show sustained engagement with both features and that customized ADs improve effectiveness, enjoyment, and immersion compared to default ADs, highlighting the value of personalized, interactive video access for BLV users.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}
Who Explains Privacy Policies to Me? Embodied and Textual LLM-Powered Privacy Assistants in Virtual Reality
Vincent Freiberger (ScaDS.AI), Moritz Dresch (LMU Munich), Florian Alt (LMU Munich), Arthur Fleig (ScaDS.AI), Viktorija Paneva (LMU Munich)
Abstract | Tags: Posters | Links:
@inproceedings{Freiberger2026WhoExplains,
title = {Who Explains Privacy Policies to Me? Embodied and Textual LLM-Powered Privacy Assistants in Virtual Reality},
author = {Vincent Freiberger (ScaDS.AI), Moritz Dresch (LMU Munich), Florian Alt (LMU Munich), Arthur Fleig (ScaDS.AI), Viktorija Paneva (LMU Munich)},
url = {http://www.medien.ifi.lmu.de/, website
https://www.linkedin.com/company/lmu-media-informatics-group/, lab's linkedin
https://www.linkedin.com/in/viktorija-paneva-hci/, author's linkedin},
doi = {10.1145/3772363.3798567},
year = {2026},
date = {2026-04-13},
urldate = {2026-04-13},
abstract = {Virtual Reality (VR) systems collect fine-grained behavioral and biometric data, yet privacy policies are rarely read or understood due to their complex language, length, and poor integration into users’ interaction workflows. To lower the barrier to informed consent at the point of choice, we explore a Large Language Model (LLM)-powered privacy assistant embedded into a VR app store to support privacy-aware app selection. The assistant is realized in two interaction modes: a text-based chat interface and an embodied virtual avatar providing spoken explanations. We report on an exploratory within-subjects study (𝑁 = 21) in which participants browsed VR productivity applications under unassisted and assisted conditions. Our findings suggest that both interaction modes support more deliberate engagement with privacy information and decision-making, with privacy scores primarily functioning as a veto mechanism rather than a primary selection driver. The impact of embodied interaction varied between participants, while textual interaction supported reflective review.},
keywords = {Posters},
pubstate = {published},
tppubtype = {inproceedings}
}